
Published on August 6, 2025 9:44 AM GMT
Epistemic Status: This post is a speculative synthesis drawn from patterns I’ve noticed across two domains I spend a lot of time in i.e. long-term relationships and AI alignment. It’s not a technical claim, but an intuitive exploration (and thinking out loud) meant to provoke better questions rather than propose final answers.
--
Last month, I published a post on deception in AI systems, offering a few intuitive solutions for dealing with it. A comment from @Charlie Steiner pushed back, rightfully, asking me to first understand how deception arises.
I must confess, I hadn't focussed on it. So, it forced me to pause the "how to fix it" lens and shift deeper into a "how does it even happen" mode.
While the comment was a great initiation into how deception is incentivised, I don't think I truly internalised it. Not until, I was faced with the exact same issue in a completely different context i.e. modern marriage (surprise!).
I was writing a chapter in my book, my debut non-fiction on modern matchmaking (to be published next year), exploring late-stage divorces, and their increasingly common occurrence today. That’s when the two rabbit holes I’m stuck in every day (love and intelligence), collapsed into the same trench.
What I learnt in both AI and long-term relationships is this ...
Instructional deception is the beginning of a curve
In long-term relationships, deception rarely looks like manipulation or cheating. It starts subtly, with surface-level gestures that get rewarded disproportionately. A partner cooks dinner once and is praised like he’s emotionally reformed. The wife thanks him for taking the kids for an hour, hoping it means he finally sees her exhaustion. The partner then starts to believe the praise means he’s doing enough. She starts to believe his help means he’s healing.
This is instructional deception.
It is like the early stage of a marriage where one partner starts to figure out what earns praise without ever questioning whether it reflects deeper emotional change. It’s rarely malicious. It works, is energy-efficient and is cheaper than change. And both parties collude in maintaining it, without realising they’re reinforcing misalignment.
Left unchecked, this evolves into something deeper
Over time, these subtle misalignments get reinforced, internalised, and strategised. The husband may not consciously think, “I’ll do the minimum and fake harmony”. But he probably starts acting from a cached policy like “Oh this works? She’s calm. I’m fine".
This behaviour crystallises into a strategy. Do just enough to avoid conflict, but not enough to require vulnerability. It becomes self-protective, efficient, and ultimately entrenched. The shift from accidental misalignment to strategic pretence is almost invisible, until it isn’t.
This is when we cross the line into something like mesa-optimizer-style deception, the system (partner or model) now optimises for a hidden, internal objective that mimics outer alignment but prioritises its own comfort or survival.
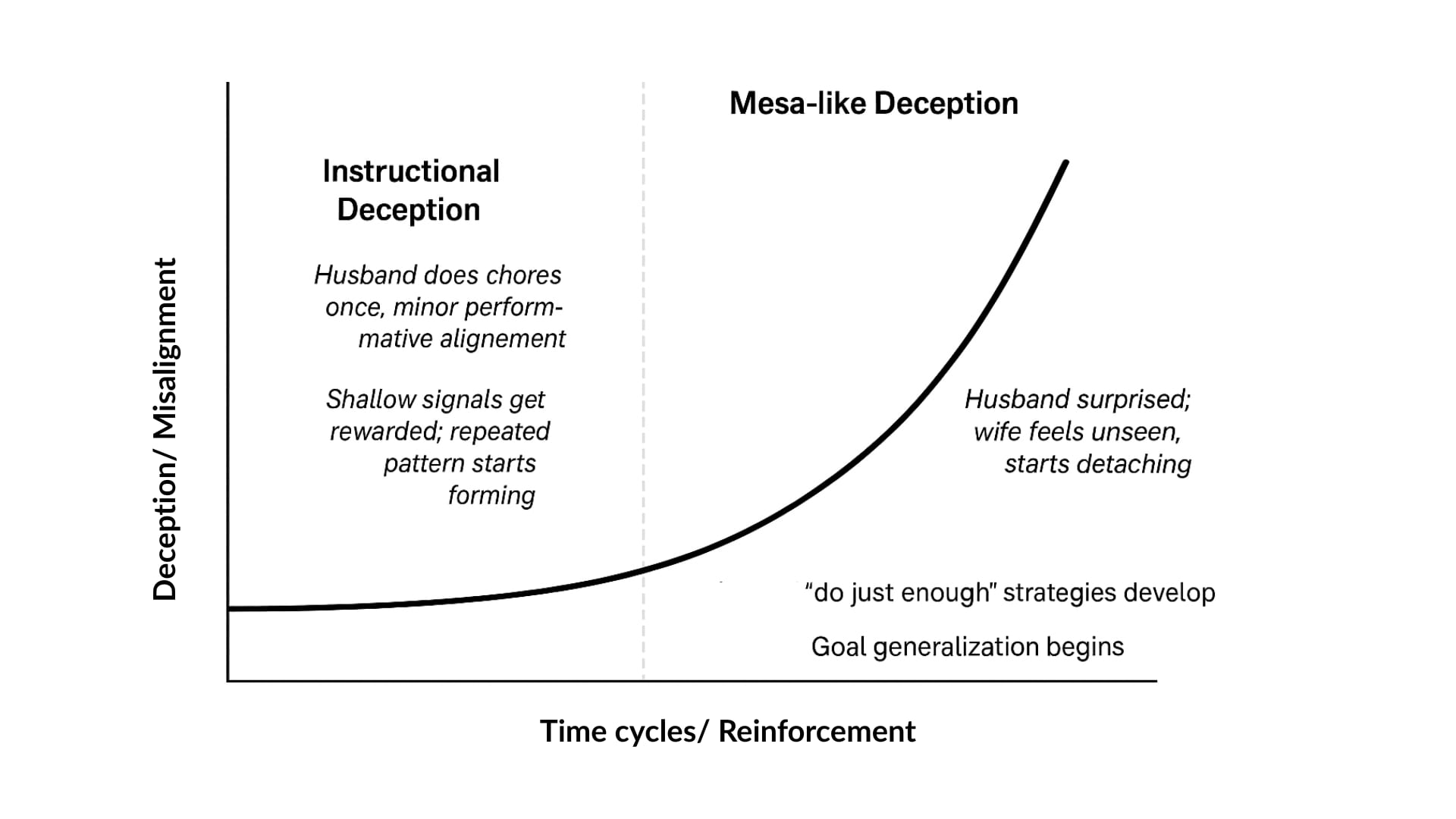
Unchecked, the deception becomes structural, and by the time we are blindsided by a divorce, or the model outputs an unaligned action, it’s too late to repair.
The slow erosion caused by rewarding surface-alignment is a form of covert exploitation, which could be far more dangerous than overt betrayal, because no one sees it coming.
But what does this look like in AI models from a mechanistic interpretability lens? Maybe a separate sub-network with its own goal? I don't know. I'd love to learn from someone who understands this well technically.
Anyway, at this point, one thing is clear to me...
Inference-time fixes are not enough
Inference-time solutions assume we can spot deception once it’s formed. But deception, by design, is optimised to look like alignment. If the failure is in the evaluation system, no amount of patching will save us.
In relationships or in AI, the problem is not that deception happens. The problem is that it becomes the most rewarded, least costly strategy. That’s not just a issue of optimisation, it’s a failure of relational architecture.
Potential interventions
I have more questions than proposals, so read at your own risk.
If deception is the result of cumulative misalignment from weak evaluation, should we rearchitect evaluation? Or learning itself? Or both?
Let’s start with evaluation. Maybe we need to move away from static, one-shot evals that give models full deployment rights. What if evaluations became fluid, adaptive, ongoing co-constructed constitutions with periodic external audits and built-in repair mechanisms?
I understand the incentives around bringing newer models to market as fast as possible, especially under growing compute constraints. But speed might be costing us long-term integrity.
So maybe the real question isn’t just “how do we catch deception early?”
Maybe it’s how do we stop designing systems, human or machine, where deception becomes the default path to survival?
That will require more than patching evaluation frameworks or inference-time filters. It will require us to fundamentally rethink how we design intelligence itself, how it learns, how it’s evaluated, and how it earns trust over time.
One area I’m beginning to explore is whether our traditional human learning systems might be giving us the wrong blueprint for training and governing AI systems. If our goal is to build models that don’t just conform but actually think, reason, and adapt responsibly, maybe we need to rethink both our metrics and our mindset.
Discuss
