
Today, we are excited to announce the availability of Open AI’s new open weight GPT OSS models, gpt-oss-120b and gpt-oss-20b, from OpenAI in Amazon SageMaker JumpStart. With this launch, you can now deploy OpenAI’s newest reasoning models to build, experiment, and responsibly scale your generative AI ideas on AWS.
In this post, we demonstrate how to get started with these models on SageMaker JumpStart.
Solution overview
The OpenAI GPT OSS models (gpt-oss-120b and gpt-oss-20b) excel at coding, scientific analysis, and mathematical reasoning tasks. Both models feature a 128K context window and adjustable reasoning levels (low/medium/high) to match specific requirements. They support external tool integration and can be used in agentic workflows through frameworks like Strands Agents, an open source AI agent SDK. With full chain-of-thought output capabilities, you get detailed visibility into the model’s reasoning process. You can use the OpenAI SDK to call your SageMaker endpoint directly by simply updating the endpoint. The models give you the flexibility to modify and customize them for your specific business needs while benefiting from enterprise-grade security and seamless scaling.
SageMaker JumpStart is a fully managed service that offers state-of-the-art foundation models (FMs) for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval. It provides a collection of pre-trained models that you can deploy, accelerating the development and deployment of machine learning (ML) applications. One of the key components of SageMaker JumpStart is model hubs, which offer a vast catalog of pre-trained models, such as OpenAI, for a variety of tasks.
You can now discover and deploy OpenAI models in Amazon SageMaker Studio or programmatically through the Amazon SageMaker Python SDK, to derive model performance and MLOps controls with Amazon SageMaker features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The models are deployed in a secure AWS environment and under your VPC controls, helping to support data security for enterprise security needs.
You can discover GPT OSS models from US East (Ohio, N. Virginia) and Asia Pacific (Mumbai, Tokyo) AWS Regions.
Throughout this example, we use the gpt-oss-120b model. These steps can be replicated with the gpt-oss-20b model as well.
Prerequisites
To deploy the GPT OSS models, you must have the following prerequisites:
- An AWS account that will contain your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker. To learn more about how IAM works with SageMaker, see AWS Identity and Access Management for Amazon SageMaker AI. Access to SageMaker Studio, a SageMaker notebook instance, or an interactive development environment (IDE) such as PyCharm or Visual Studio Code. We recommend using SageMaker Studio for straightforward deployment and inference. To deploy GPT OSS models, make sure you have access to the recommended instance types based on the model size. You can find these instance recommendations on the SageMaker JumpStart model card. The default instance type for both these models is p5.48xlarge, but you can also use other P5 family instances where available. To verify you have the necessary service quotas, complete the following steps:
- On the Service Quotas console, under AWS Services, choose Amazon SageMaker. Check that you have sufficient quota for the required instance type for endpoint deployment. Make sure at least one of these instance types is available in your target Region. If needed, request a quota increase and contact your AWS account team for support.
Deploy gpt-oss-120b through the SageMaker JumpStart UI
Complete the following steps to deploy gpt-oss-120b through SageMaker JumpStart:
- On the SageMaker console, choose Studio in the navigation pane. First-time users will be prompted to create a domain. If not, choose Open Studio. On the SageMaker Studio console, access SageMaker JumpStart by choosing JumpStart in the navigation pane. On the SageMaker JumpStart landing page, search for
gpt-oss-120b using the search box. 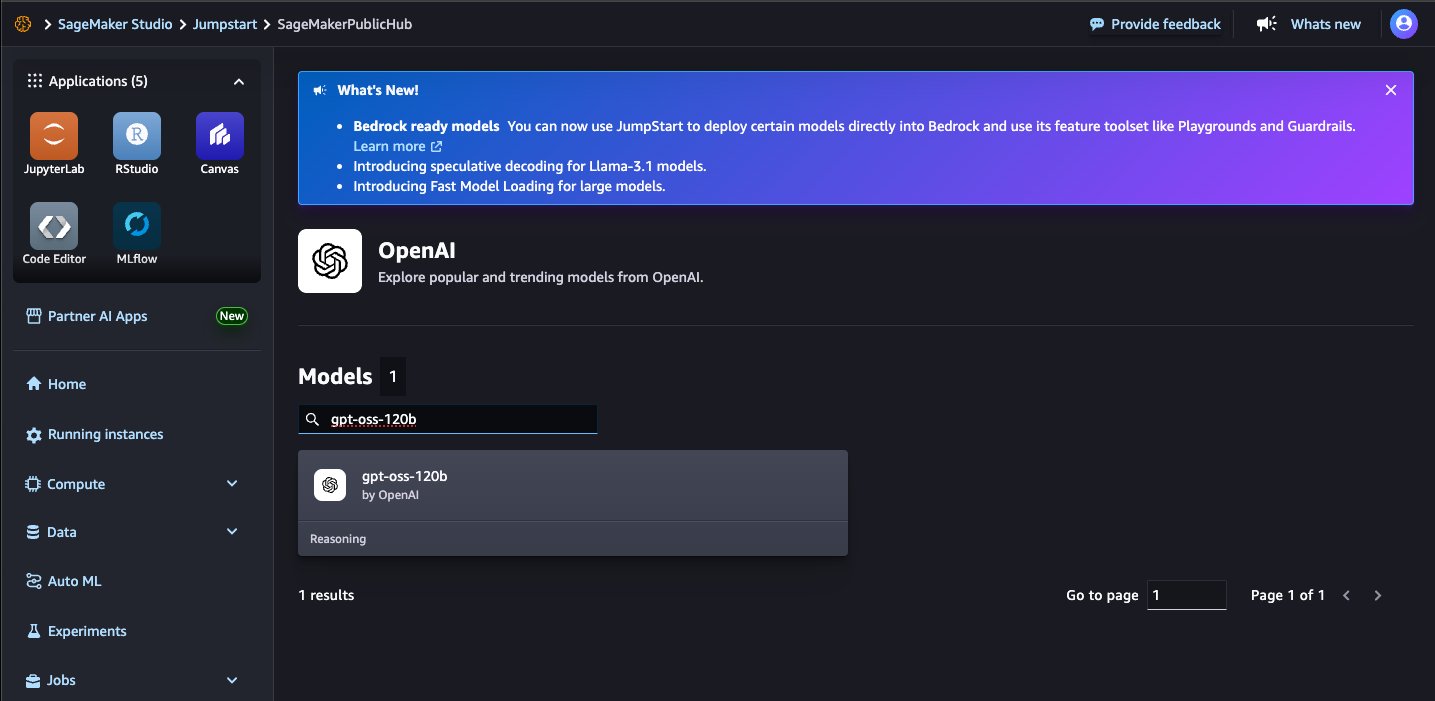
- Choose a model card to view details about the model such as license, data used to train, and how to use the model. Before you deploy the model, review the configuration and model details from the model card. The model details page includes the following information:
- The model name and provider information. A Deploy button to deploy the model.
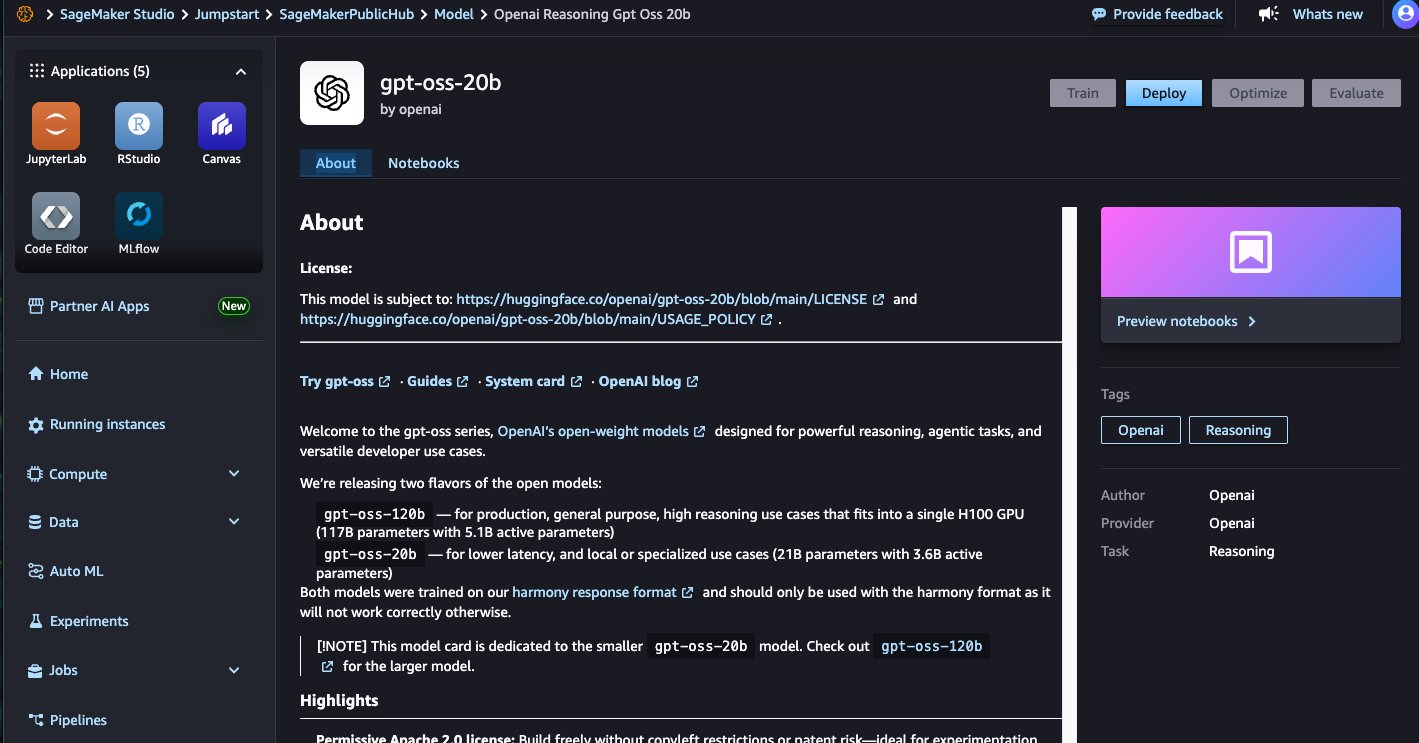
- Choose Deploy to proceed with deployment.
- For Endpoint name, enter an endpoint name (up to 50 alphanumeric characters). For Number of instances, enter a number between 1–100 (default: 1). For Instance type, select your instance type. For optimal performance with
gpt-oss-120b, a GPU-based instance type such as p5.48xlarge is recommended. 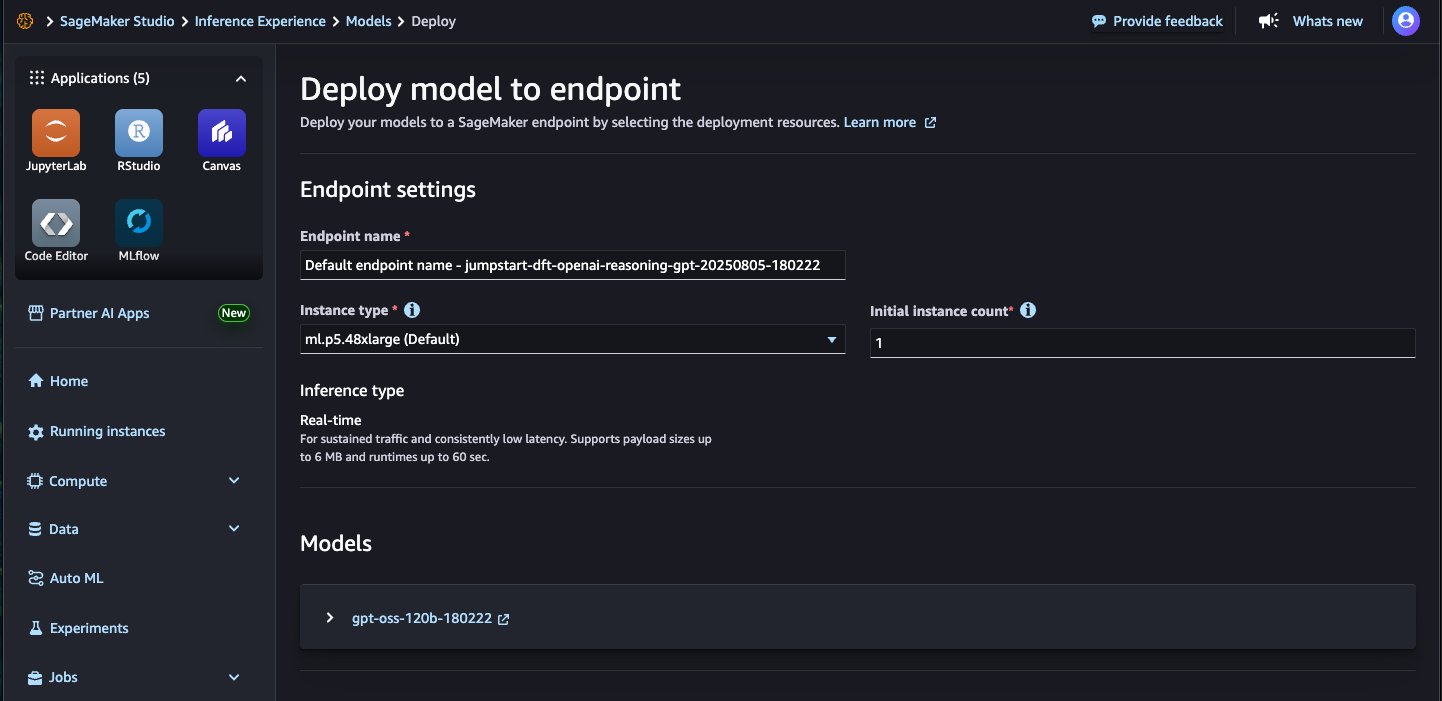
- Choose Deploy to deploy the model and create an endpoint.
When deployment is complete, your endpoint status will change to InService. At this point, the model is ready to accept inference requests through the endpoint. When the deployment is complete, you can invoke the model using a SageMaker runtime client and integrate it with your applications.
Deploy gpt-oss-120b with the SageMaker Python SDK
To deploy using the SDK, start by selecting the gpt-oss-120b model, specified by the model_id with the value openai-reasoning-gpt-oss-120b. You can deploy your choice of model on SageMaker using the Python SDK examples in the following sections. Similarly, you can deploy gpt-oss-20b using its model ID.
Enable web search on your model with EXA
By default, models in SageMaker JumpStart run in network isolation. The GPT OSS models come with a built-in tool for web search using EXA, a meaning-based web search API powered by embeddings. To use this tool, OpenAI requires customers get an API key from EXA and pass this key as an environment variable to their JumpStartModel instance when deploying it through the SageMaker Python SDK. The following code details how to deploy the model on SageMaker with network isolation disabled and pass in the EXA API key to the model:
You can change these configurations by specifying other non-default values in JumpStartModel. The end user license agreement (EULA) value must be explicitly defined as True to accept the terms. With the preceding deployment, because network isolation is set at deployment time, turning it back on requires creating a new endpoint.
Optionally, you can deploy your model with the JumpStart default values (with network isolation enabled) as follows:
Run inference with the SageMaker predictor
After the model is deployed, you can run inference against the deployed endpoint through the SageMaker predictor:
We get the following response:
Function calling
The GPT OSS models were trained on the harmony response format for defining conversation structures, generating reasoning output and structuring function calls. The format is designed to mimic the OpenAI Responses API, so if you have used that API before, this format should hopefully feel familiar to you. The model should not be used without using the harmony format. The following example showcases an example of tool use with this format:
We get the following response:
Clean up
After you’re done running the notebook, make sure to delete the resources that you created in the process to avoid additional billing. For more details, see Delete Endpoints and Resources.
Conclusion
In this post, we demonstrated how to deploy and get started with OpenAI’s GPT OSS models (gpt-oss-120band gpt-oss-20b) on SageMaker JumpStart. These reasoning models bring advanced capabilities for coding, scientific analysis, and mathematical reasoning tasks directly to your AWS environment with enterprise-grade security and scalability.
Try out the new models, and share your feedback in the comments.
About the Authors
Pradyun Ramadorai, Senior Software Development Engineer
Malav Shastri, Software Development Engineer
Varun Morishetty, Software Development Engineer
Evan Kravitz, Software Development Engineer
Benjamin Crabtree, Software Development Engineer
Shen Teng, Software Development Engineer
Loki Ravi, Senior Software Development Engineer
Nithin Vijeaswaran, Specialist Solutions Architect
Breanne Warner, Enterprise Solutions Architect
Yotam Moss, Software Development Manager
Mike James, Software Development Manager
Sadaf Fardeen, Software Development Manage
Siddharth Shah, Principal Software Development Engineer
June Won, Principal Product Manager
