
Most companies and use cases do not care about PhD-level capabilities. They just want an AI model to depend on with absolute reliability, for the simple tasks in life.
Imagine a highly competent, dependable, reliable assistant, who does all your chores–instead of the caffeine-overloaded genius, who sometimes works when it “feels like it”--but otherwise causes more harm than good half the time.
That's what we just built with the Featherless.ai Action-R1 model & agent, which achieved SotA (State-of-the-Art) in the REAL (Realistic Evaluations for Agents Leaderboard) benchmark.
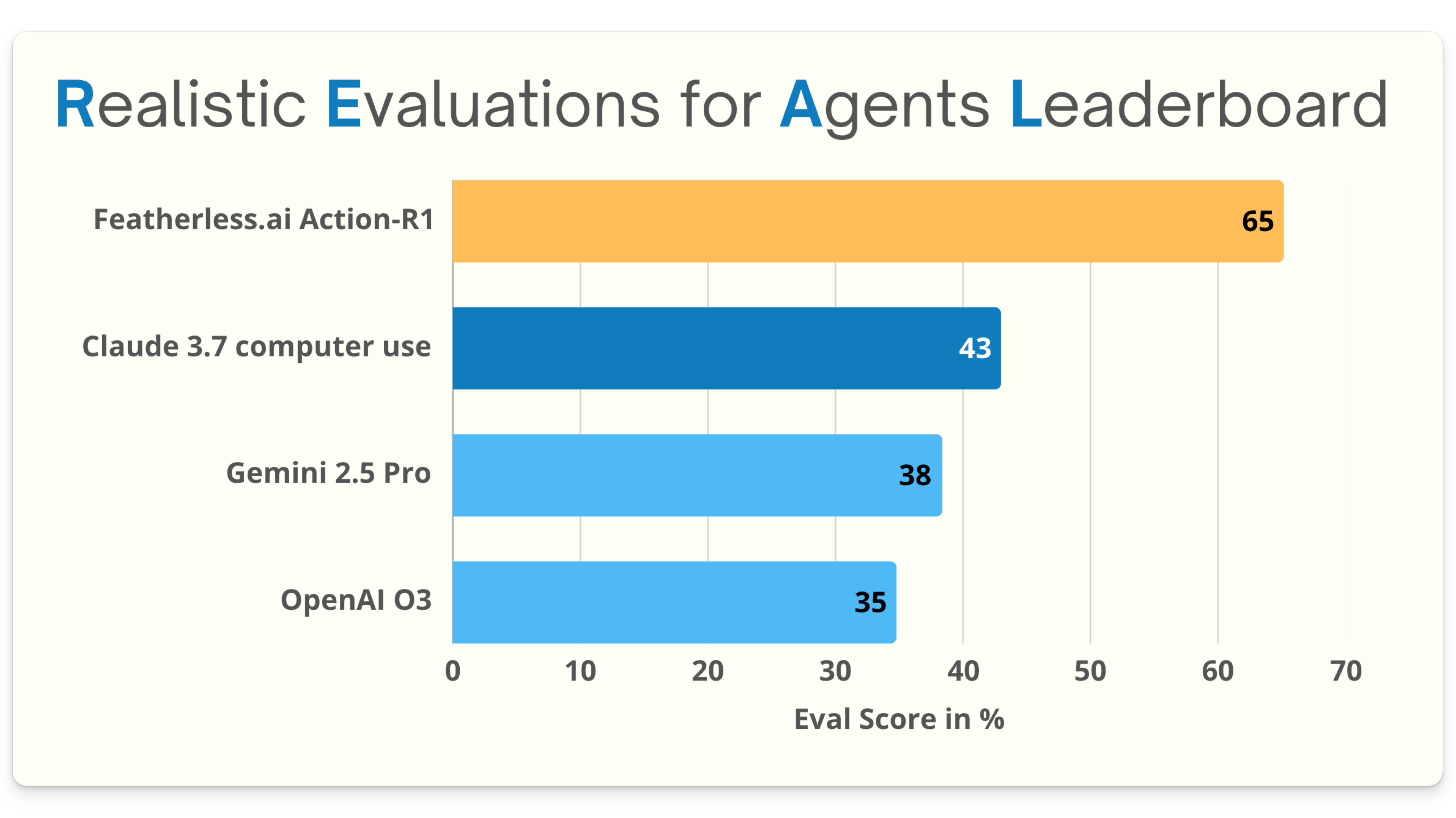
Our AI agent (test result at link) achieved a 65% success rate on the REAL benchmark. This makes it nearly 50% better than Anthropic computer use (result link), the next best model & framework, by a major lab at 42%
Working–end-to-end automation across the real web use cases
What is the REAL benchmark?
What is interesting about the REAL benchmark is that it tests over 110 practical real-world tasks. These are not university-level knowledge tasks, but real-world chores that reflect what people do online every day, like booking flights, organizing and replying emails, and shopping for groceries. Basically, office desk work.
These are tested using a controlled test replica, which mirrors 11 major websites, including Airbnb, Amazon, Gmail, LinkedIn, and Uber.
The paper for the benchmark can be found here
Why does reliability matter?
Frontier AI agents have been plateauing at around 43% overall task completion. We hit 65%, leapfrogging it by 22 percentage points.
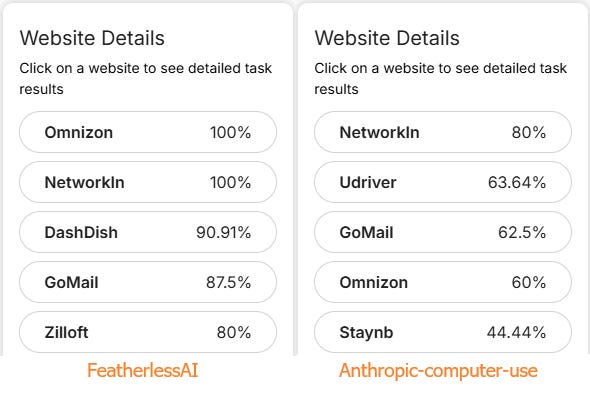
More importantly, on certain sites, such as the Omnizon (aka Amazon clone), our agent reached a 100% success rate, while the next best managed 60%.
And the 99%+ distinction matters.
Because you can now rely on this model and agent for tasks in this domain.
If a model is only at 50% success rate at a category of task, you spend more time and energy “babysitting” the models. In several cases, the model will require human intervention which can take more bandwidth than the task itself.
Raising reliability means that you can hand off tasks to the AI, eliminating the frustration many workers face with AI in the enterprise.
For the first time, we have built an AI agent you can rely on for tasks within a handful of platforms with 99%+ success. We will eventually expand to 99%+ reliability for all web platforms.
How we did it
We partnered with the team at UI-licious, who automate end-to-end testing for their customers with AI at scale, building on their experience and knowledge in UI test automation and their proprietary PetaByte scale dataset which they have built up over the years on UI testing.
Together, we co-built a specialized AI action model and agent harness. This helps the AI understand instructions and how to navigate complex and dynamic UIs.
As a bonus, these AI agents are not just navigating and completing tasks. They are finding and issuing bug reports, which we will be following up with the eval maintainers on 😉

The bigger picture: attacking multi-billion dollar markets
The $3B+ Robotic Process Automation (RPA) market and the $20B+ UI testing market are dominated by brittle tools that break easily and require constant maintenance, where AI agents achieve about 60% reliability.
Today’s RPA tools like UIPath operate like glorified macros, breaking when user interfaces change or when variability is introduced. Businesses spend millions maintaining these systems, fixing broken RPA scripts.
Agentic AI is different. It learns. It adapts. It interacts with interfaces the way humans do—observing, interpreting, and acting based on context. It allows automation over dynamic interfaces.
And we’re just getting started.
As we scale our AI research in the open source space, we will be working alongside industry partners to build reliable AI Agents and models for their own industry specific use, with their own proprietary datasets.
So we will be increasing reliability, not just in automated UI testing, but in all future domains as well, with industry partners from accounting to legal.
Raising reliability means unlocking the 90% of AI projects that fail to enter production within enterprises, as the AI was just “not reliable enough” for day-to-day office tasks.
Raising reliability means bringing into production your AI agent into the market.
If you are interested in partnering with us, and making your AI more SoTA-reliable, please reach out to us.
How can we try this new action model & agent?
Look out for a follow-up launch announcement with our design partners at UI-licious.
This AI action model and agent will be co-launched on both platforms.
For early access, you can sign up here:
https://forms.gle/wxwQ2z12xf1KzFvPA
Priority access will be given to portfolio companies among our investors and users.
