


Chain-of-Thought (CoT) prompting enables large language models (LLMs) to perform step-by-step logical deductions in natural language. While this method has proven effective, natural language may not be the most efficient medium for reasoning. Studies indicate that human mathematical reasoning does not primarily rely on language processing, suggesting that alternative approaches could enhance performance. Researchers aim to refine how LLMs process reasoning, balancing accuracy with computational efficiency.
The challenge of reasoning in LLMs stems from their reliance on explicit CoT, which requires generating detailed explanations before arriving at a final answer. This approach increases computational overhead and slows down inference. Implicit CoT methods attempt to internalize reasoning without generating explicit reasoning tokens, but these methods have historically underperformed compared to explicit CoT. A major obstacle lies in designing models that can efficiently process reasoning internally while maintaining accuracy. A solution that eliminates excessive computational burden without sacrificing performance is critical for scaling up reasoning capabilities in LLMs.
Previous implicit CoT methods have primarily relied on curriculum learning strategies, which progressively internalize reasoning steps. One such method, Coconut, gradually replaces explicit CoT tokens with continuous representations while maintaining a language modeling objective. However, this approach has limitations, including error propagation and gradual forgetting during training. As a result, Coconut, despite improvements over baseline models, still lags behind explicit CoT methods by a significant margin. Implicit CoT approaches have consistently failed to match the reasoning performance of explicitly generated CoT.
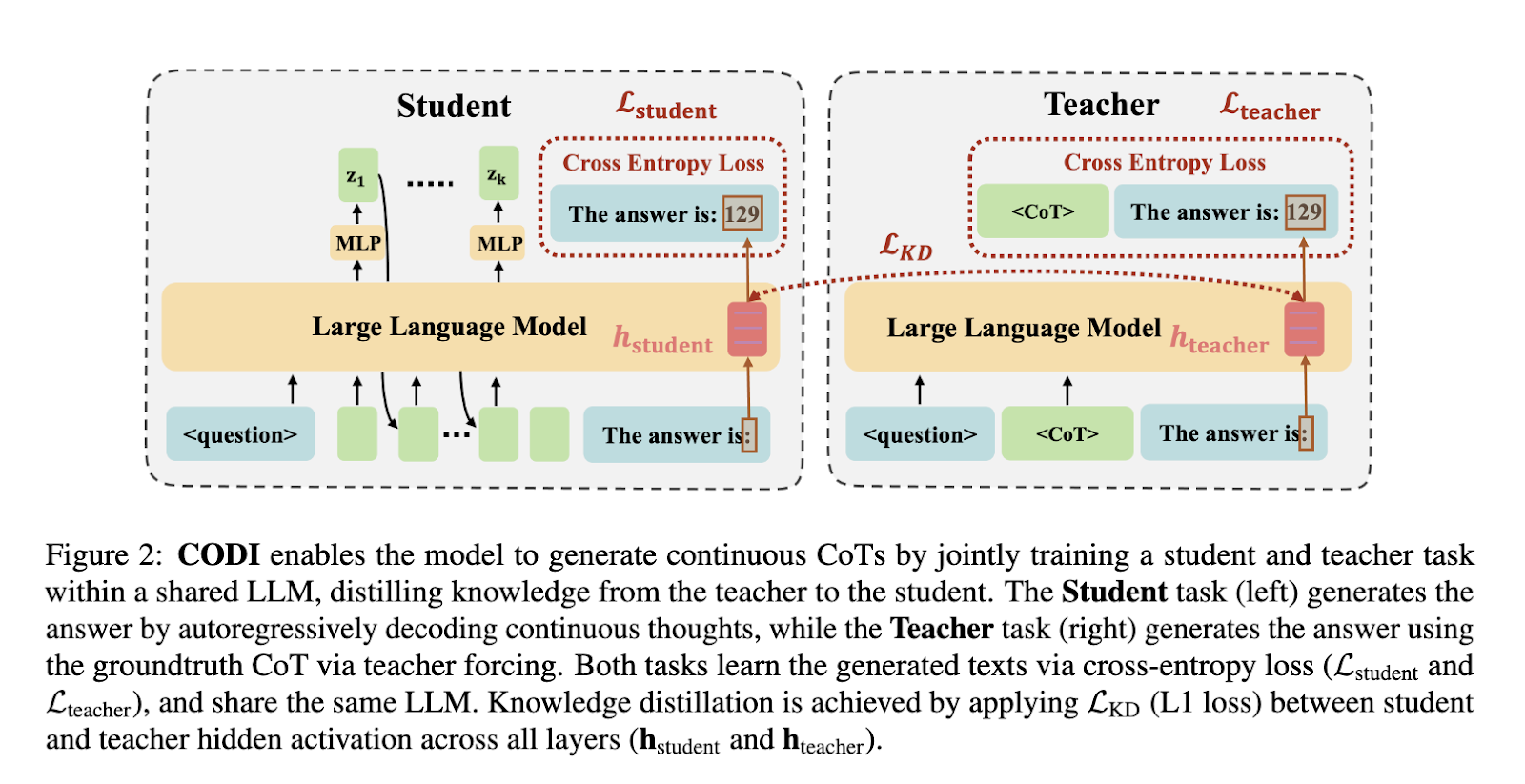
Researchers from King’s College London and The Alan Turing Institute introduced CODI (Continuous Chain-of-Thought via Self-Distillation) as a novel framework to address these limitations. CODI distills explicit CoT reasoning into a continuous space, allowing LLMs to perform logical deductions internally without generating explicit CoT tokens. The method employs self-distillation, where a single model functions as both a teacher and a student, aligning their hidden activations to encode reasoning within a compact latent space. By leveraging this technique, CODI effectively compresses reasoning without sacrificing performance.
CODI consists of two key learning tasks: explicit CoT generation and continuous CoT reasoning. The teacher model follows standard CoT learning by processing natural language step-by-step reasoning and generating explicit CoT sequences. The student model, in contrast, learns to internalize reasoning within a compact latent representation. To ensure proper knowledge transfer, CODI enforces alignment between these two processes using an L1 distance loss function. Unlike previous approaches, CODI directly injects reasoning supervision into the hidden states of the model, allowing for more efficient training. Instead of relying on multiple training stages, CODI applies a single-step distillation approach, ensuring that information loss and forgetting issues inherent in curriculum learning are minimized. The process involves selecting a specific hidden token that encodes crucial reasoning information, providing the model can effectively generate continuous reasoning steps without explicit tokens.
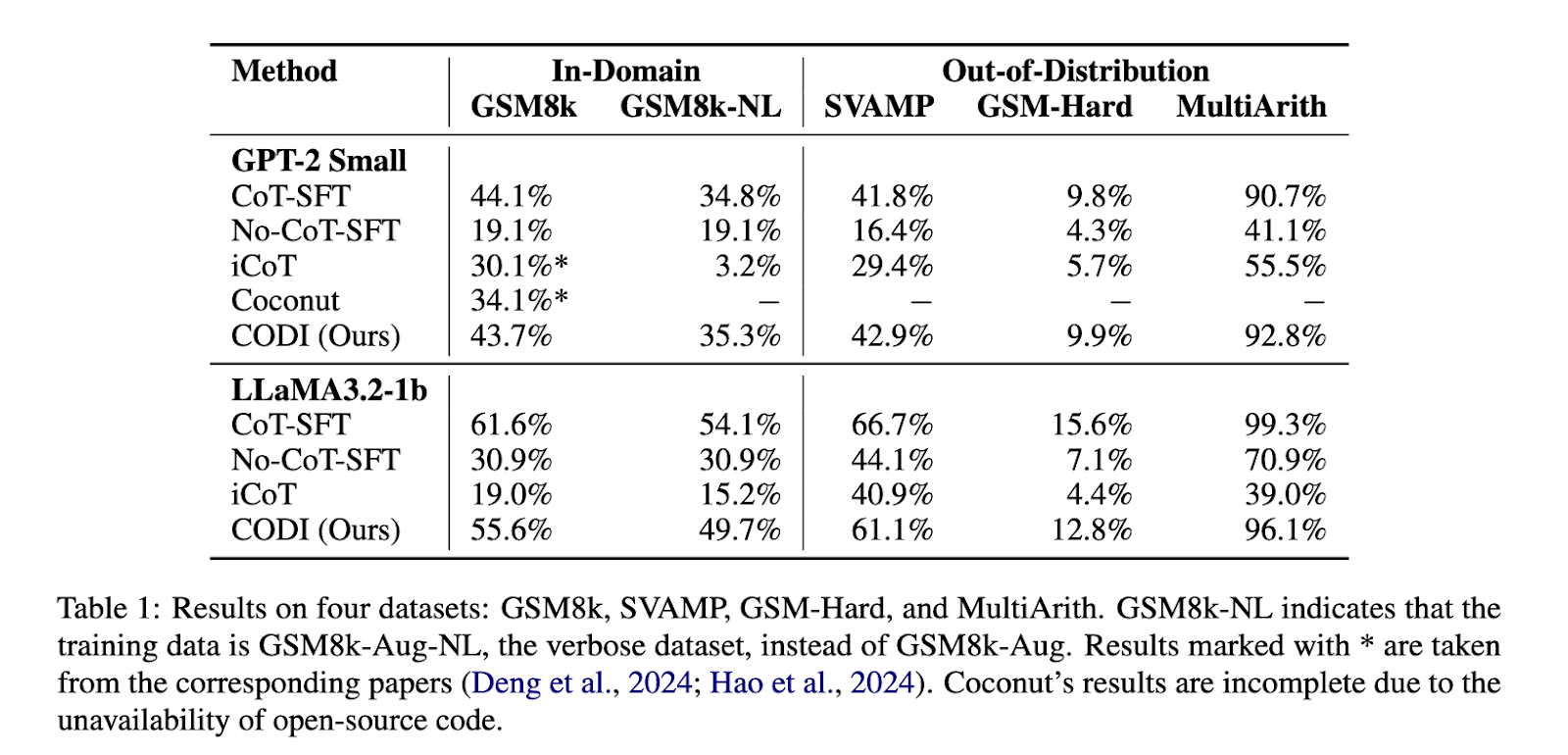
Experimental results demonstrate that CODI significantly outperforms previous implicit CoT methods and is the first to match the accuracy of explicit CoT in mathematical reasoning tasks. On the GSM8k dataset, CODI achieves a 3.1× compression ratio while maintaining performance comparable to explicit CoT. It surpasses Coconut by 28.2% in accuracy. Further, CODI is scalable and adaptable to various CoT datasets, making it suitable for more complex reasoning problems. Performance benchmarks indicate that CODI achieves a reasoning accuracy of 43.7% on GSM8k with a GPT-2 model, compared to 34.1% with Coconut. When tested on larger models such as LLaMA3.2-1b, CODI attains 55.6% accuracy, demonstrating its ability to scale effectively. Regarding efficiency, CODI processes reasoning steps 2.7 times faster than traditional CoT and 5.9 times faster when applied to more verbose reasoning datasets. Its robust design allows it to generalize to out-of-domain benchmarks, outperforming CoT-SFT on datasets such as SVAMP and MultiArith.

CODI marks a significant improvement in LLM reasoning, effectively bridging the gap between explicit CoT and computational efficiency. Leveraging self-distillation and continuous representations introduces a scalable approach to AI reasoning. The model retains interpretability, as its continuous thoughts can be decoded into structured reasoning patterns, providing transparency in the decision-making process. Future research could explore CODI’s application in more complex multimodal reasoning tasks, expanding its benefits beyond mathematical problem-solving. The framework establishes implicit CoT as a computationally efficient alternative and a viable solution for reasoning challenges in advanced AI systems.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 80k+ ML SubReddit.


 It’s operated using an easy-to-use CLI
It’s operated using an easy-to-use CLI  and native client SDKs in Python and TypeScript
and native client SDKs in Python and TypeScript  .
.The post This AI Paper Introduces CODI: A Self-Distillation Framework for Efficient and Scalable Chain-of-Thought Reasoning in LLMs appeared first on MarkTechPost.
