


Mathematical Large Language Models (LLMs) have demonstrated strong problem-solving capabilities, but their reasoning ability is often constrained by pattern recognition rather than true conceptual understanding. Current models are heavily based on exposure to similar proofs as part of their training, confining their extrapolation to new mathematical problems. This constraint restricts LLMs from engaging in advanced mathematical reasoning, especially in problems requiring the differentiation between closely related mathematical concepts. An advanced reasoning strategy commonly lacking in LLMs is the proof by counterexample, a central method of disproving false mathematical assertions. The absence of sufficient generation and employment of counterexamples hinders LLMs in conceptual reasoning of advanced mathematics, hence diminishing their reliability in formal theorem verification and mathematical exploration.
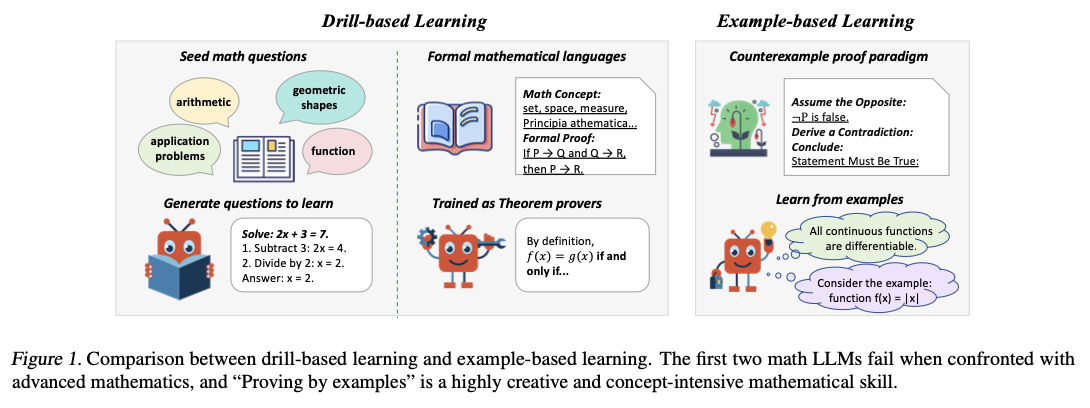
Previous attempts to improve mathematical reasoning in LLMs have been categorized into two general approaches. The first approach, synthetic problem generation, trains LLMs on vast datasets generated from seed math problems. For example, WizardMath uses GPT-3.5 to generate problems of varying levels of difficulty. The second approach, formal theorem proving, trains models to work with proof systems such as Lean 4, as in Draft-Sketch-Prove and Lean-STaR, that assist LLMs in structured theorem proving. Although these approaches have enhanced problem-solving ability, they have severe limitations. Synthetic question generation generates memorization and not genuine understanding, leaving models vulnerable to failure in the face of novel problems. Formal theorem-proving techniques, on the other hand, are limited by being grounded in structured mathematical languages that limit their application to various mathematical contexts. These limitations underscore the need for an alternative paradigm—a paradigm that is concerned with conceptual understanding as opposed to pattern recognition.
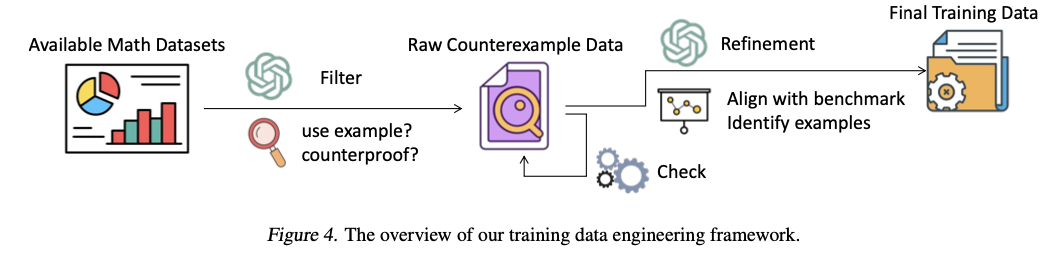
To address these limitations, a counterexample-driven mathematical reasoning benchmark is introduced, known as COUNTERMATH. The benchmark is specifically constructed to assess and enhance LLMs’ use of counterexamples in proof. The innovations encompass a high-quality benchmark, data engineering process, and thorough model assessments. COUNTERMATH is comprised of 1,216 mathematical assertions, each of which needs a counterexample to disprove. The problems are hand-curated from university textbooks and extensively validated by experts. To enhance LLMs’ counterexample-based reasoning, an automated data-gathering process is implemented, filtering and refining mathematical proof data to obtain counterexample-based reasoning examples. The efficacy of state-of-the-art mathematical LLMs, such as OpenAI’s o1 model and fine-tuned open-source variants, is rigorously examined on COUNTERMATH. By diverting the focus toward example-based reasoning from exclusive theorem-proving, this method initiates a novel and under-explored route to training mathematical LLMs.

COUNTERMATH is constructed based on four core mathematical disciplines: Algebra, Topology, Real Analysis, and Functional Analysis. The data is built in a multi-step process. First, mathematical statements are gathered from textbooks and converted to structured data via OCR. Mathematicians then review and annotate each problem for logical consistency and accuracy. Professional translations are performed as the original data is in Chinese, followed by additional checks. An in-task data engineering framework is also presented to automatically retrieve training data for counterexample-based reasoning. GPT-4o filtering and refinement techniques are applied in this framework to extract relevant proofs from outside sources such as ProofNet and NaturalProof. Refinement is done to ensure each proof explicitly illustrates counterexamples so that LLMs can learn counterexample-based reasoning more effectively.
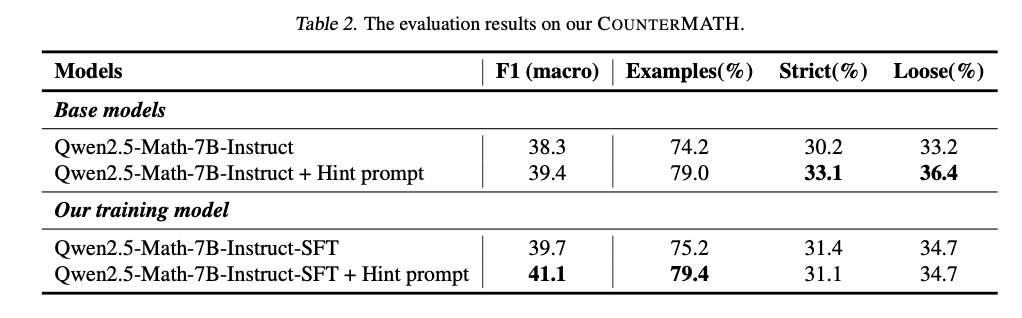
The evaluation of state-of-the-art mathematical LLMs on COUNTERMATH reveals significant gaps in counterexample-driven reasoning. The majority of the models do not pass judgment on whether a statement is true or false using counterexamples, reflecting a profound conceptual weakness. Performance is also mixed across mathematical areas, with algebra and functional analysis performing better, and topology and real analysis still being very challenging due to their abstract nature. Open-source models perform worse than proprietary models, with only a few having moderate conceptual reasoning. Fine-tuning with counterexample-based data, however, significantly enhances performance, with better judgment accuracy and example-based reasoning. A fine-tuned model, with only 1,025 counterexample-based training samples, performs significantly better than its baseline versions and has strong generalization to out-of-distribution mathematical tests. A detailed evaluation reported in Table 1 below shows performance comparisons based on F1 scores and reasoning consistency metrics. Qwen2.5-Math-72B-Instruct performs best (41.8 F1) among open-source models but falls behind proprietary models like GPT-4o (59.0 F1) and OpenAI o1 (60.1 F1). Fine-tuning leads to significant gains, with Qwen2.5-Math-7B-Instruct-SFT + Hint prompt achieving 41.1 F1, affirming the effectiveness of counterexample-based training.

This proposed method presents COUNTERMATH, a counterexample-based reasoning benchmark designed to improve LLMs’ conceptual mathematical abilities. The utilization of well-curated problem sets and an automated data refinement process demonstrates that existing LLMs are not proficient in deep mathematical reasoning but can be greatly enhanced with counterexample-based training. These results imply that future AI research needs to be focused on enhancing conceptual understanding and not exposure-based learning. Counterexample reasoning is not only essential in mathematics but also in logic, scientific investigation, and formal verification, and this method can thus be extended to a broad variety of AI-driven analytical tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.

The post Boosting AI Math Skills: How Counterexample-Driven Reasoning is Transforming Large Language Models appeared first on MarkTechPost.
