NVIDIA is excited to announce the release of Nemotron-CC, a 6.3-trillion-token English language Common Crawl dataset for pretraining highly accurate large language models (LLMs), including 1.9 trillion tokens of synthetically generated data. One of the keys to training state-of-the-art LLMs is a high-quality pretraining dataset, and recent top LLMs, such as the Meta Llama series, were trained on vast amounts of data comprising 15 trillion tokens.But little is known about the exact composition of these 15 trillion tokens. Nemotron-CC aims to remedy this and enable the wider community to train highly accurate LLMs. Internet crawl data, typically from Common Crawl, is generally the largest source of tokens. Recent open Common Crawl datasets, such as FineWeb-Edu and DCLM, have shown how to greatly improve benchmark accuracies over relatively short token horizons. However, this has been accomplished at the cost of removing 90% of data. This limits the suitability for long token horizon training, such as 15 trillion tokens for Llama 3.1. Nemotron-CC fills this gap and shows how to transform Common Crawl data into a high-quality dataset suitable for training LLMs better than Llama 3.1 8B through a combination of classifier ensembling, synthetic data rephrasing, and reduced reliance on heuristic filters.ResultsShown in Figure 1 are MMLU scores when training 8B parameter models for 1 trillion tokens, varying only the 73% English Common Crawl portion of the training data. Compared to the leading open English Common Crawl dataset DCLM, the high-quality subset Nemotron-CC-HQ increases the MMLU by +5.6.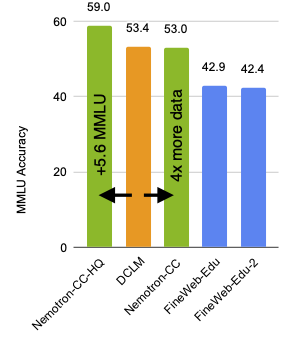 Figure 1. MMLU scores for 8B parameter models trained for 1 trillion tokens Furthermore, the full 6.3-trillion-token dataset matches DCLM on MMLU, but contains four times more unique real tokens. This unlocks effective training over a long token horizon: an 8 billion parameter model trained for 15 trillion tokens, of which 7.2 trillion came from Nemotron-CC, is better than the Llama 3.1 8B model: +5 on MMLU, +3.1 on ARC-Challenge, and +0.5 on average across ten diverse tasks.Key insightsSome of the key insights that led to these results include:Ensembling different model-based classifiers can help select a larger and more diverse set of high quality tokens.Rephrasing can effectively reduce noise and errors in low-quality data and produce diverse variants with fresh unique tokens from high-quality data, leading to better results in downstream tasks.Disabling traditional non-learned heuristic filters for high-quality data can further boost high quality token yield without hurting accuracy.Data curation steps Using NVIDIA NeMo Curator, we extracted and cleaned data from Common Crawl and then: Filtered it for the English languagePerformed global fuzzy deduplication as well as exact substring deduplication Leveraged model-based filters such as DCLM, fineweb-edu for quality classificationApplied various heuristic and perplexity filters to further remove lower-quality dataWe also leveraged synthetic data generation pipelines to generate ~2 trillion tokens of synthetic data. The full recipe including the synthetic data generation pipelines will be merged into the NVIDIA/NeMo-Curator GitHub repo soon. To receive updates, star the repo.ConclusionNemotron-CC is an open, large, high-quality English Common Crawl dataset that enables pretraining highly accurate LLMs over both short and long token horizons. In the future, we hope to release more datasets that are key ingredients for state-of-the-art LLM pretraining, such as a specialized math pretraining dataset.AcknowledgmentsWe thank the Common Crawl Foundation for hosting the dataset. We thank Pedro Ortiz Suarez for valuable feedback that improved the paper and Greg Lindahl for help with improving the data formatting and layout.
Figure 1. MMLU scores for 8B parameter models trained for 1 trillion tokens Furthermore, the full 6.3-trillion-token dataset matches DCLM on MMLU, but contains four times more unique real tokens. This unlocks effective training over a long token horizon: an 8 billion parameter model trained for 15 trillion tokens, of which 7.2 trillion came from Nemotron-CC, is better than the Llama 3.1 8B model: +5 on MMLU, +3.1 on ARC-Challenge, and +0.5 on average across ten diverse tasks.Key insightsSome of the key insights that led to these results include:Ensembling different model-based classifiers can help select a larger and more diverse set of high quality tokens.Rephrasing can effectively reduce noise and errors in low-quality data and produce diverse variants with fresh unique tokens from high-quality data, leading to better results in downstream tasks.Disabling traditional non-learned heuristic filters for high-quality data can further boost high quality token yield without hurting accuracy.Data curation steps Using NVIDIA NeMo Curator, we extracted and cleaned data from Common Crawl and then: Filtered it for the English languagePerformed global fuzzy deduplication as well as exact substring deduplication Leveraged model-based filters such as DCLM, fineweb-edu for quality classificationApplied various heuristic and perplexity filters to further remove lower-quality dataWe also leveraged synthetic data generation pipelines to generate ~2 trillion tokens of synthetic data. The full recipe including the synthetic data generation pipelines will be merged into the NVIDIA/NeMo-Curator GitHub repo soon. To receive updates, star the repo.ConclusionNemotron-CC is an open, large, high-quality English Common Crawl dataset that enables pretraining highly accurate LLMs over both short and long token horizons. In the future, we hope to release more datasets that are key ingredients for state-of-the-art LLM pretraining, such as a specialized math pretraining dataset.AcknowledgmentsWe thank the Common Crawl Foundation for hosting the dataset. We thank Pedro Ortiz Suarez for valuable feedback that improved the paper and Greg Lindahl for help with improving the data formatting and layout.

