


Language models have become increasingly expensive to train and deploy. This has led researchers to explore techniques such as model distillation, where a smaller student model is trained to replicate the performance of a larger teacher model. The idea is to enable efficient deployment without compromising performance. Understanding the principles behind distillation and how computational resources can be optimally allocated between student and teacher models is crucial to improving efficiency.
The increasing size of machine learning models has resulted in high costs and sustainability challenges. Training these models requires substantial computational resources, and inference demands even more computation. The associated costs can surpass pretraining expenses, with inference volumes reaching billions of daily tokens. Moreover, large models present logistical challenges such as increased energy consumption and difficulty in deployment. The necessity to reduce inference costs without sacrificing model capabilities has motivated researchers to seek solutions that balance computational efficiency and effectiveness.
Earlier approaches to address computational constraints in large model training include compute-optimal training and overtraining. Compute-optimal training determines the best-performing model size and dataset combination within a given compute budget. Overtraining extends training data usage beyond compute-optimal parameters, yielding compact, effective models. However, both techniques have trade-offs, such as increased training duration and diminishing performance improvements. While compression and pruning methods have been tested, they often lead to a decline in model effectiveness. Therefore, a more structured approach, such as distillation, is needed to enhance efficiency.
Researchers from Apple and the University of Oxford introduce a distillation scaling law that predicts the performance of a distilled model based on compute budget distribution. This framework enables the strategic allocation of computational resources between teacher and student models, ensuring optimal efficiency. The research provides practical guidelines for compute-optimal distillation and highlights scenarios where distillation is preferable over supervised learning. The study establishes a clear relationship between training parameters, model size, and performance by analyzing large-scale distillation experiments.
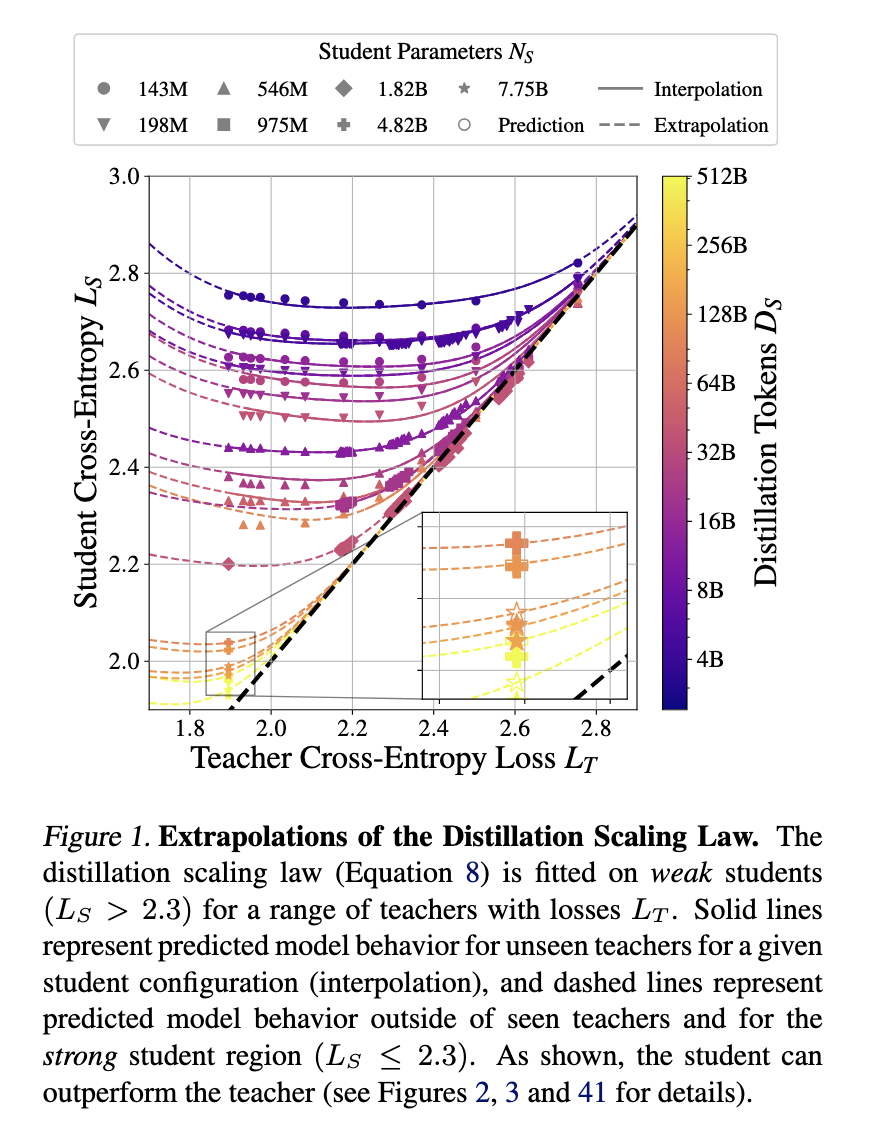
The proposed distillation scaling law defines how student performance depends on the teacher’s cross-entropy loss, dataset size, and model parameters. The research identifies a transition between two power-law behaviors, where a student’s ability to learn depends on the relative capabilities of the teacher. The study also addresses the capacity gap phenomenon, which suggests that stronger teachers sometimes produce weaker students. The analysis reveals that this gap is due to differences in learning capacity rather than model size alone. Researchers demonstrate that when compute is appropriately allocated, distillation can match or surpass traditional supervised learning methods in terms of efficiency.
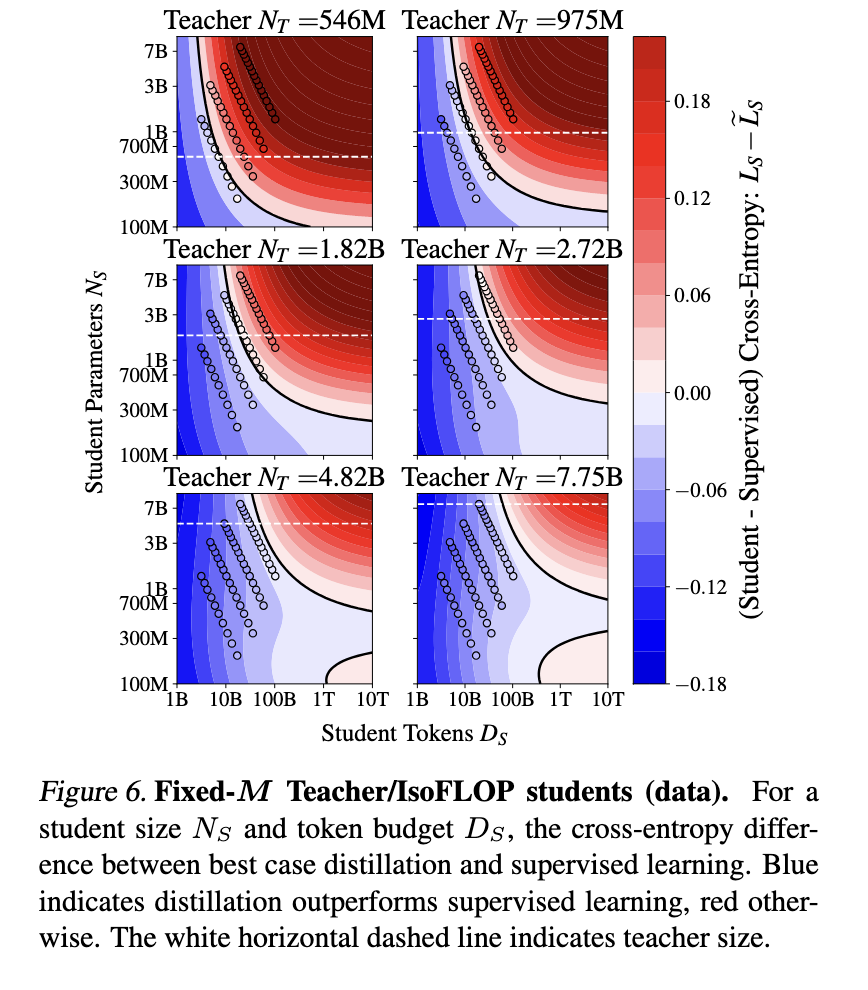
Empirical results validate the scaling law’s effectiveness in optimizing model performance. The study conducted controlled experiments on student models ranging from 143 million to 12.6 billion parameters, trained using up to 512 billion tokens. Findings indicate that distillation is most beneficial when a teacher model exists and the compute or training tokens allocated to the student do not exceed a threshold dependent on model size. Supervised learning remains the more effective choice if a teacher needs to be trained. The results show that student models trained using compute-optimal distillation can achieve lower cross-entropy loss than those trained using supervised learning when compute is limited. Specifically, experiments demonstrate that student cross-entropy loss decreases as a function of teacher cross-entropy, following a predictable pattern that optimizes efficiency.
The research on distillation scaling laws provides an analytical foundation for improving efficiency in model training. Establishing a methodology for compute allocation it offers valuable insights into reducing inference costs while preserving model performance. The findings contribute to the broader objective of making AI models more practical for real-world applications. By refining training and deployment strategies, this work enables the development of smaller yet powerful models that maintain high performance at a reduced computational cost.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 75k+ ML SubReddit.
 Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)
Recommended Open-Source AI Platform: ‘IntellAgent is a An Open-Source Multi-Agent Framework to Evaluate Complex Conversational AI System’ (Promoted)The post This AI Paper from Apple Introduces a Distillation Scaling Law: A Compute-Optimal Approach for Training Efficient Language Models appeared first on MarkTechPost.
