


Large language models (LLMs) have rapidly advanced multimodal large language models (LMMs), particularly in vision-language tasks. Videos represent complex, information-rich sources crucial for understanding real-world scenarios. However, current video-language models encounter significant challenges in temporal localization and precise moment detection. Despite extensive training in video captioning and question-answering datasets, these models struggle to identify and reference specific temporal segments within video content. The fundamental limitation lies in their inability to precisely search and extract relevant information from large redundant video materials. This challenge becomes increasingly critical as the demand for evidence-based, moment-specific video analysis increases.
Existing research on video-language models has explored multiple approaches to bridge visual and language understanding. Large image-language models initially focused on utilizing image encoders in language models, with methods like BLIP using learnable query transformers to connect visual and language domains. Initial methods, like Video-LLaVA’s 8-frame sampling technique, uniformly selected a fixed number of frames but struggled with processing longer videos. Advanced techniques like LongVU and Kangaroo developed adaptive compression mechanisms to reduce visual tokens across spatial and temporal dimensions. However, current models still face significant challenges in accurately capturing and representing temporal nuances in video content.
To this end, researchers from Meituan Inc. have proposed TimeMarker, a novel video-language model designed to address temporal localization challenges in video understanding. TimeMarker introduces innovative techniques to enhance semantic perception and temporal awareness in video content. The model integrates Temporal Separator Tokens to mark specific moments within videos precisely and implements an AnyLength mechanism for dynamic frame sampling. TimeMarker can effectively process short and long video sequences using adaptive token merging. Moreover, it utilizes diverse datasets, including transformed temporal-related video question-answering datasets, to improve the model’s understanding of temporal nuances.
TimeMarker’s architecture is fundamentally based on the LLaVA framework, utilizing a Vision Encoder to process video frames and a cross-modality Projector to translate visual tokens into the language space. The model introduces two key innovative components: Temporal Separator Tokens Integration and the AnyLength mechanism. Temporal Separator Tokens are strategically inserted with video frame tokens, enabling the LLM to recognize and encode absolute temporal positions within the video. The AnyLength mechanism coupled with an Adaptive Token Merge module, allows the model to handle videos of different lengths efficiently. This approach ensures flexible and precise temporal understanding across different video content types.
TimeMarker demonstrates exceptional performance across various temporal understanding tasks. Researchers included the experimental results of Short and General Video Evaluation, Long Video Evaluation, and the Effects of Temporal Separator Tokens. The model shows superior temporal awareness in experimental evaluations by accurately identifying clock digits, locating specific events, and reasoning about temporal contexts in multi-turn dialogues from a 2-minute life-record video. It accurately identifies clock digits, locating relevant events, and reasoning about something strange. Moreover, TimeMarker can perform OCR tasks sequentially within a specified time interval.
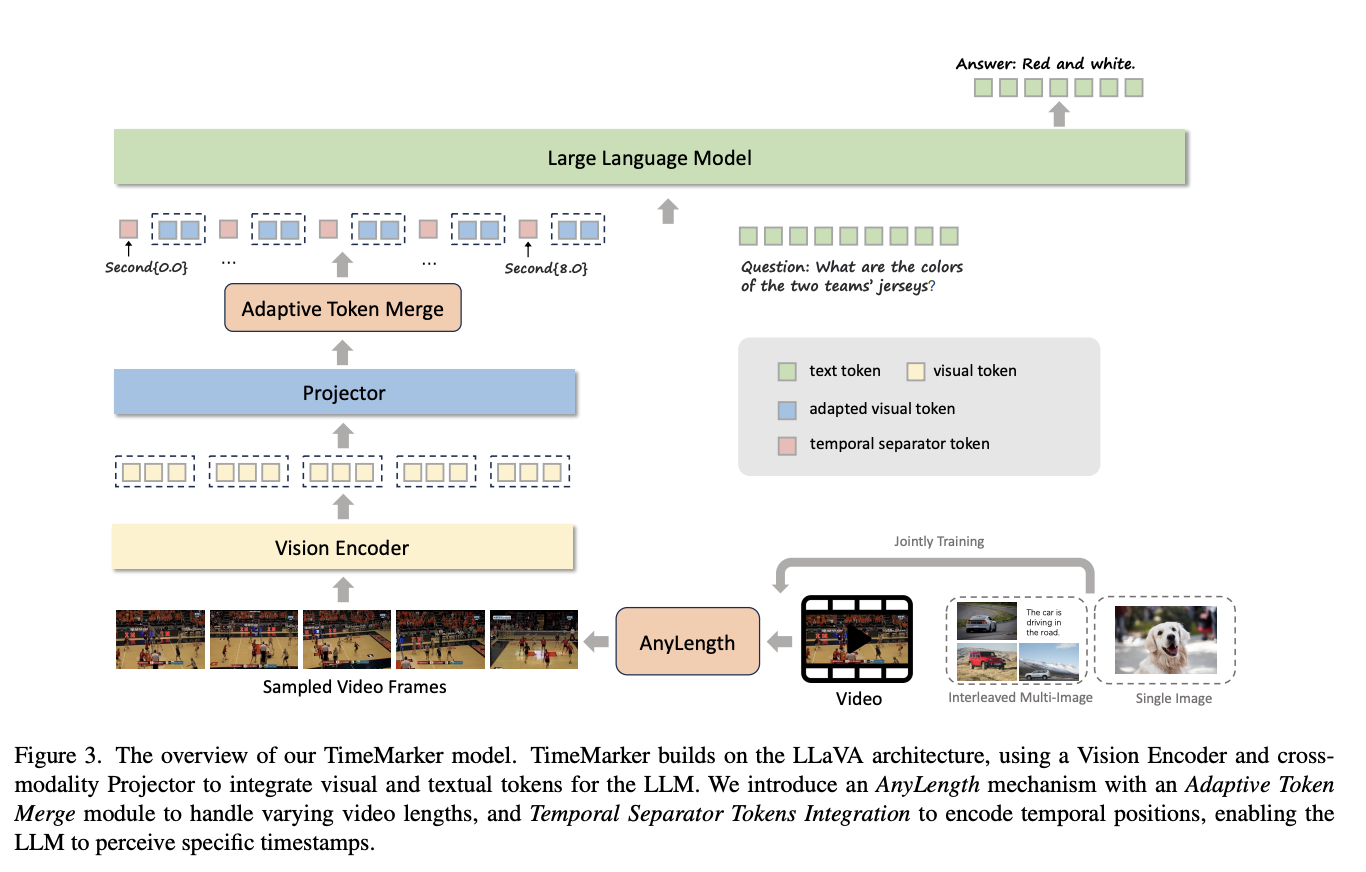
In this paper, researchers from Meituan Inc. introduced TimeMarker which represents a significant advancement in video-language models, addressing critical challenges in temporal localization and video understanding. By introducing Temporal Separator Tokens and the AnyLength mechanism, the model effectively encodes temporal positions and adapts to videos of varying lengths. Its innovative approach enables precise event detection, temporal reasoning, and comprehensive video analysis across different content types. The model’s superior performance across multiple benchmarks demonstrates its potential to transform video-language interaction, setting a new standard for temporal understanding in multimodal AI systems.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 60k+ ML SubReddit.
 [Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
[Must Attend Webinar]: ‘Transform proofs-of-concept into production-ready AI applications and agents’ (Promoted)
The post TimeMarker: Precise Temporal Localization for Video-LLM Interactions appeared first on MarkTechPost.
